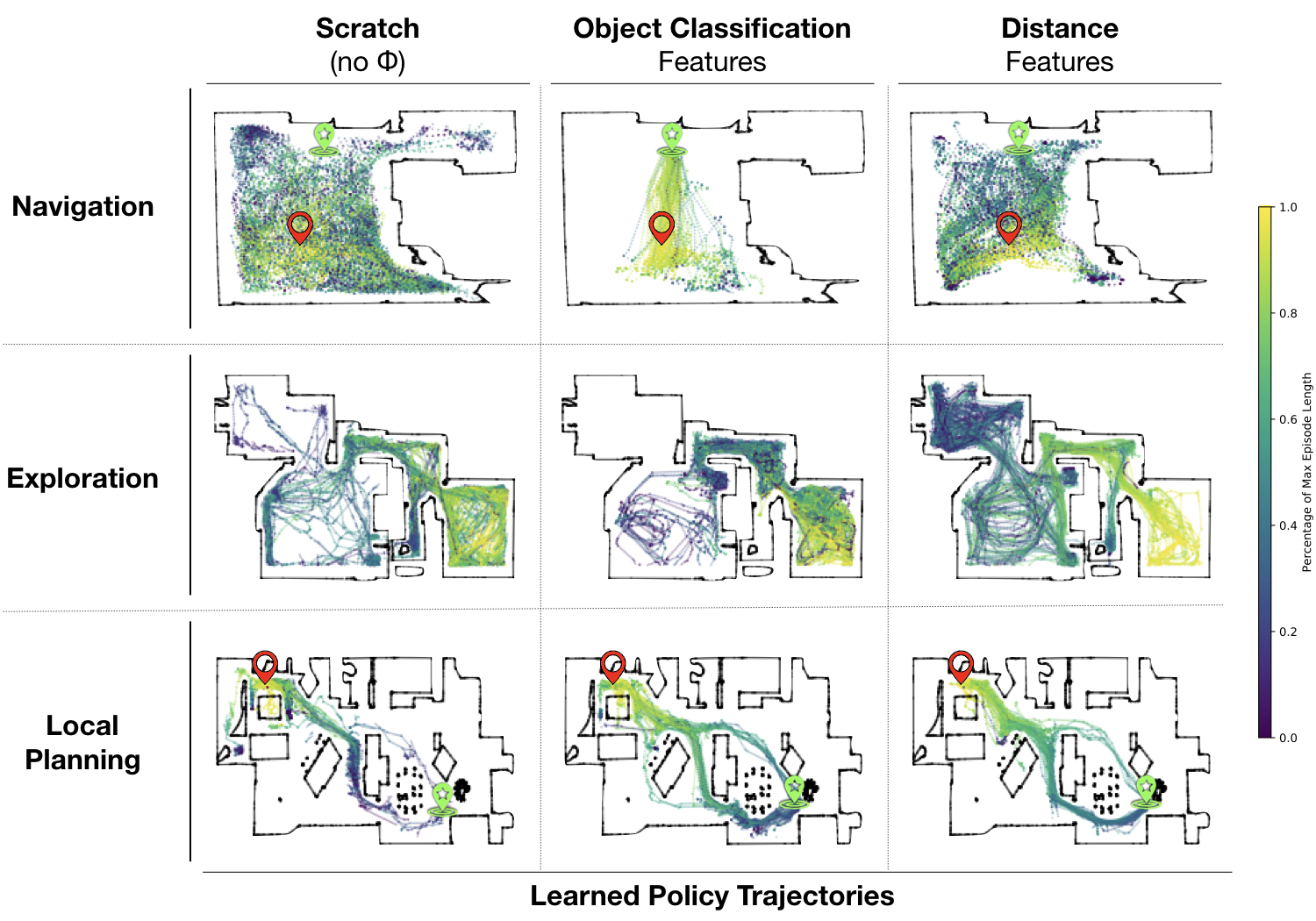
Studied Questions
We distill our analysis into three questions:
HI. Whether mid-level vision improves the learning speed (answer: yes)
HII. Whether mid-level vision provides an advantage when generalizing to unseen spaces (yes)
HIII. Whether a fixed mid-level feature can suffice or if a set of features is required for supporting arbitrary motor tasks (a set is essential).
We use statistical tests to answer these questions where appropriate.
HI. Whether mid-level vision improves the learning speed (answer: yes)
HII. Whether mid-level vision provides an advantage when generalizing to unseen spaces (yes)
HIII. Whether a fixed mid-level feature can suffice or if a set of features is required for supporting arbitrary motor tasks (a set is essential).
We use statistical tests to answer these questions where appropriate.
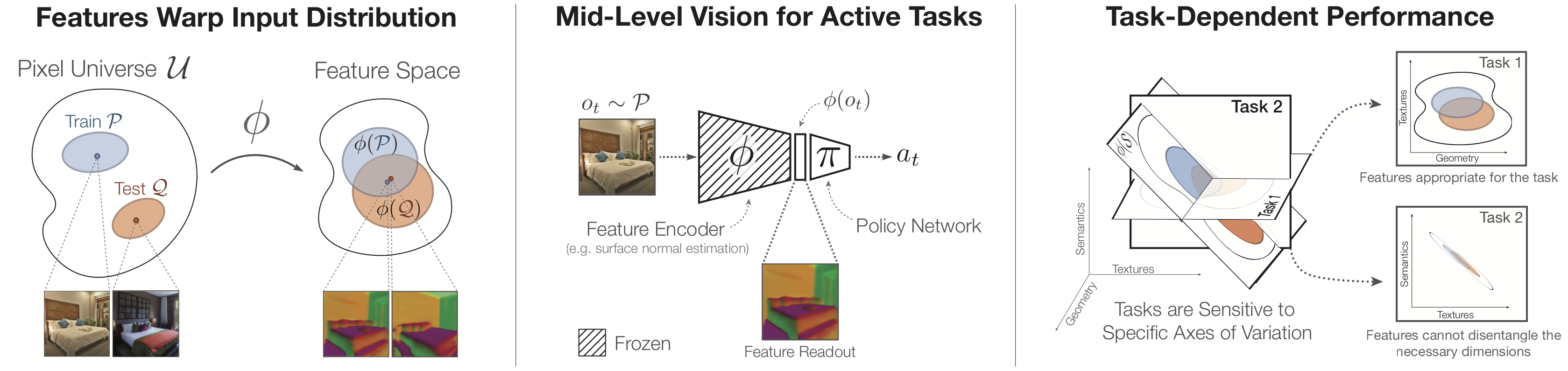
The figure below illustrates our approach: Left: Features warp the input distribution, potentially making the train and test distributions look more similar to the agent. Middle: The learned features from fixed encoder networks are used as the state for training policies in RL. Right: Downstream tasks prefer features that contain enough information to solve the task while remaining invariant to the task-irrelevant details.